

Qu'entend-on exactement lorsqu'on dit d'une personne qu'elle est mince, grosse, athlétique ou enveloppée ? Des dizaines de mots peuvent être utilisés pour décrire la taille et la forme du corps, et leur signification spécifique peut parfois sembler varier d'une personne à l'autre. On sait que les patientes souffrant d'anorexie mentale ont une conception déformée de la grosseur et du poids normal, au moins lorsqu'il s'agit de leur propre corps. En caractérisant mieux ce que les gens ont en tête quand ils utilisent des "étiquettes de poids" (weight labels), on pourrait mieux comprendre les distorsions de l'image corporelle et l'insatisfaction corporelle.
Plusieurs études ont suivi le même principe pour essayer de sonder le contenu des weight labels : les participantes et participants doivent indiquer sur une échelle picturale quel est le corps qui correspond le mieux à différents mots (voir l’image ci-dessous pour un exemple). Ces résultats indiquent deux choses. D’abord, chaque mot était associé à des types de corps légèrement différents, même quand ils pouvaient sembler synonymes au premier abord. Il est aussi important de noter que les réponses étaient plus variables pour certains mots que d’autres. Ainsi, chaque mot ne décrit pas forcément les corps avec le même niveau de précision. Est-ce que cette variabilité révèle une variabilité inter-individuelle ou une incertitude concernant le mot lui-même ?


Pour le savoir, nous avons mené une expérience pour mieux décrire cette variabilité intrinsèque aux weight labels. Cette question pouvait être importante dans le cadre de ma thèse, qui portait sur l’influence d’autrui sur notre représentation corporelle. Nous voulions ainsi mieux caractériser les types de corps associés à des qualificatifs comme “gros” ou “mince”.
Le principe de notre étude était de décrire chaque label avec une distribution de probabilité, pouvant s’étendre sur plusieurs types de corps, plutôt qu’avec un unique point de donnée. Nous voulions donc décrire chaque label par sa position (sa tendance centrale, sa valeur moyenne), mais aussi par sa dispersion (son étalement, sa précision). Autre détail : nous voulions une distribution qui puisse être asymétrique. Enfin, il fallait pouvoir la paramétrer facilement à partir des réponses des participants. La distribution que nous avons finalement utilisée s’appelle la distribution PERT ou bêta-PERT. Elle ne demande que trois points de données : un minimum, un maximum, et un mode. Elle présente aussi l’avantage d’être lisse (contrairement à une distribution triangulaire).
La CGFRS (Computer-Generated Figure Rating Scale) de Moussally et al. (2017), que nous avons utilisée dans notre étude.
Nous avons demandé aux participantes de faire correspondre les labels de poids à des images. Pour chaque mot, elles devaient indiquer le corps qui correspondait le mieux (mode), mais aussi les corps le plus mince (minimum) et le plus gros (maximum) auxquels on pouvait appliquer le mot. La variabilité associée à chaque mot a donc pu être représentée de deux manières :
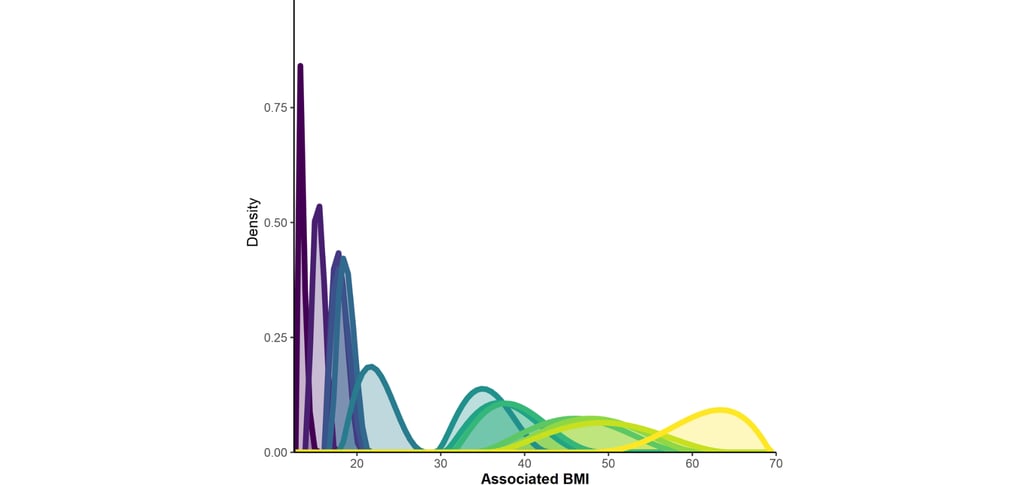
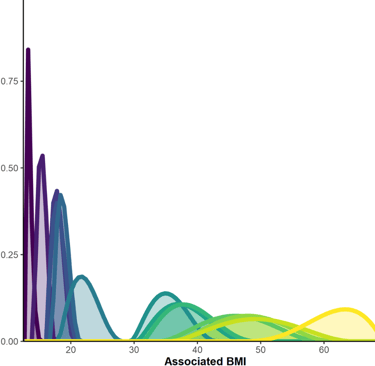
en prenant la moyenne des distributions construites par chaque participante, on a une image de la variabilité interindividuelle du sens moyen du mot
en prenant la moyenne de chaque paramètre en utilisant les réponses de toutes les participantes, on obtient une image moyenne du sens du mot (à quel point le mot a un sens large ou étroit)
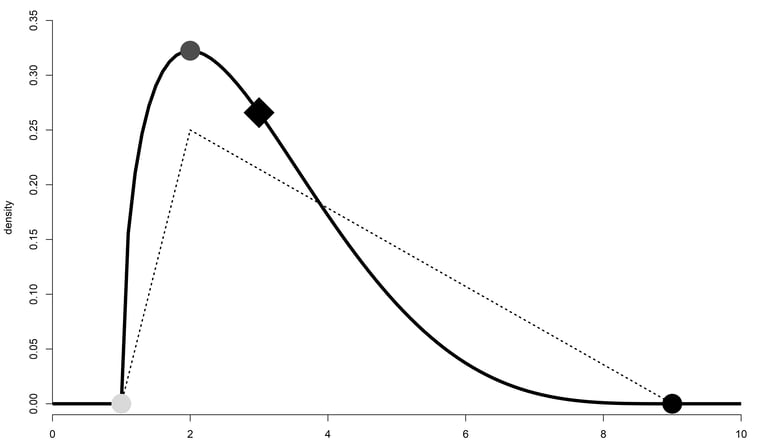
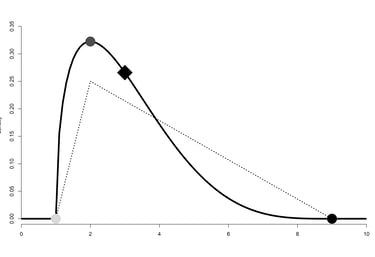
Un exemple de distribution PERT avec son minimum (point gris clair), son maximum (point noir), et son mode (point gris foncé). Le losange indique la moyenne de la distribution. Les pointillés correspondent à une distribution triangulaire qui aurait les trois mêmes paramètres.
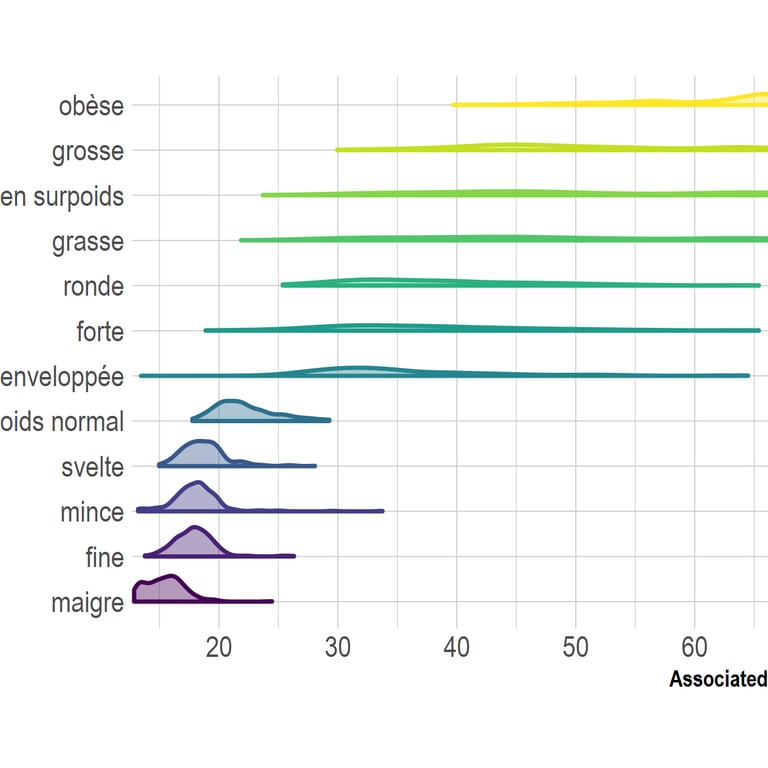
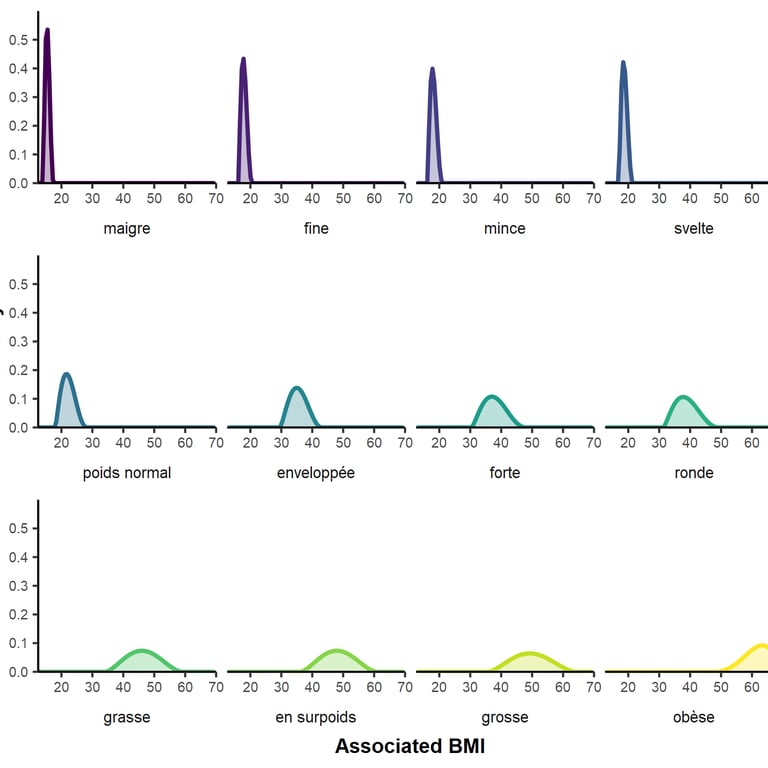
Chaque label est associé à des IMC variables d'une personne à l'autre (image 1)... mais correspond aussi à une corpulence plus ou moins précise (image 2). Les images peuvent être agrandies en cliquant dessus.
Bien sûr, comme toujours, le résultat n'est pas entièrement satisfaisant. D’abord, nous aurions besoin de valider l'outil et de vérifier sa fidélité test-retest. Il serait aussi préférable de laisser varier le type de distribution lui-même : certaines pourraient être bimodales, d'autres plus uniformes ou encore moins lisses. Si on veut développer cette méthode, il sera également essentiel d'évaluer dans quelle mesure les résultats dépendent des stimuli spécifiques que nous avons utilisées. Enfin, pour l'instant, l'étude s’est concentrée sur les réponses de femmes à des corps de femmes, mais une analyse sur des populations et des stimuli plus diversifiés serait nécessaire pour généraliser nos conclusions.
Reste que le principe me paraît intéressant et ouvre des perspectives, en particulier en psychologie de la santé. On sait que les patientes souffrant de troubles du comportement alimentaire, et en particulier d’anorexie mentale, ont une représentation distordue de leur propre corps. Certains résultats indiquent que les femmes ayant une insatisfaction corporelle élevée conçoivent différemment la limite entre le poids normal et le surpoids. Dans un contexte de recherche, la modélisation que nous avons proposée pourrait permettre de mieux comprendre ces distorsions du vocabulaire lié au poids et leurs relations à l’insatisfaction corporelle. Dans un contexte clinique, elle pourrait aussi aider à caractériser les préconceptions des patientes à propos du poids normal et du surpoids. D’autres recherches sont nécessaires pour vérifier ces perspectives.
Avis aux chercheuses et chercheurs : si la méthode vous paraît intéressante, j'ai le vague projet de faire une application en ligne qui permette de tester les mots de son choix et/ou de contribuer à une base de données plus diverse. N'hésitez pas à me contacter pour me signaler si un tel outil pourrait vous intéresser.
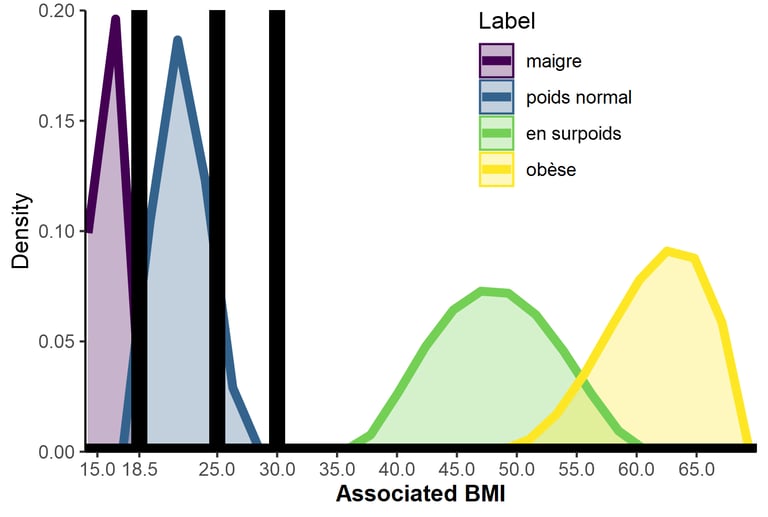
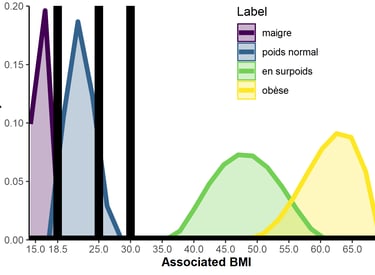
Autre exemple de nos résultats : dans notre échantillon, les femmes semblaient surestimer l'IMC nécessaire pour être considéré comme obèse selon les normes de l'Organisation Mondiale de la Santé. Ce résultat est cohérent avec d'autres travaux, mais attention quand même : cela pourrait être dû à l'échelle utilisée ou aux mots que nous avons testés.