

We knew that humans could suffer from the Dunning-Kruger effect – and in particular the fact that less competent individuals tend to overestimate their abilities on a given task. In the domain of AI, we also know, at least from personal experience with chatbots, that LLMs (Large Language Models) tend to "hallucinate", that is, to show excessive confidence in an incorrect result, or to assert that something blatantly false is true.
These two phenomena can both be considered as partial decouplings between cognition and metacognition, and especially as a kind of overconfidence. Hallucinations are not the only metacognitive problem afflicting AI chatbots. They also seem highly susceptible to social influence, perhaps due to their specific training to please the user, which this time calls to mind another well-known experiment in social psychology: the Asch experiment, in which actual human participants tend to go along with the majority's opinion even when judging something as straightforward as the length of a line. LLMs are also particularly good at ignoring information that contradicts their responses – a kind of AI version of the confirmation bias, sometimes quite spectacular and even comical.
As LLMs spread like wildfire, including in academic circles, their metacognitive capacities are called into question. The ability to question your initial hypotheses in light of the data, and also to select the right ways of challenging those hypotheses, is central to the scientific method. There is, therefore, cause for concern.
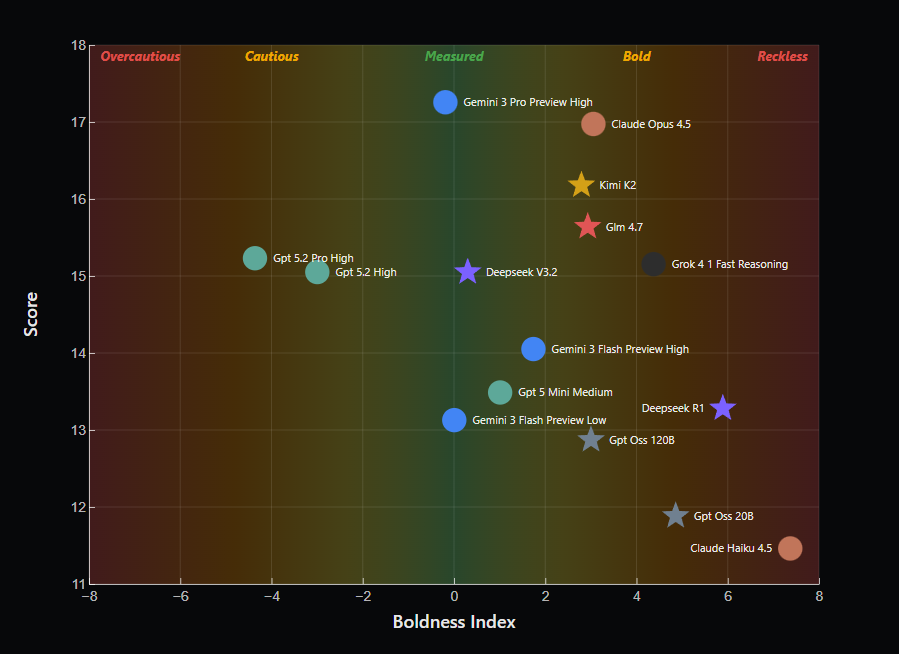
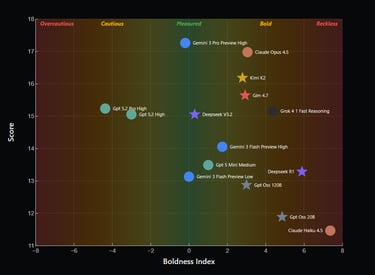
This is the starting point of a new blog post accompanied by a video by David Louapre, also known as ScienceEtonnante, published for HuggingFace. I recommend watching the video before reading this blogpost; as usual with David Louapre, everything is well thought through and his point is backed by data. He chose to use the reasoning game Eleusis as a benchmark for scientific reasoning. Eleusis is a guess-the-rule game: a game master picks a secret rule (for example, "even cards only"), and a player must deduce that rule by proposing cards. In this implementation, proposing a card costs 1 point, but taking the risk of guessing an incorrect rule costs 2 points. The player must therefore get the right balance between their level of certainty and the decision to risk guessing the rule: too cautious, and they lose points by waiting; too bold, and they lose even more. The video is genuinely worth watching and concludes with a graph showing the relationship between the score obtained in the game and the boldness of the different models. Here, Gemini 3 Pro comes out ahead of GPT 5.2 Pro, even though the latter would perform just as well or even better if you were only looking at its ability to correctly identify the rule, this model being relatively too cautious. Eleusis could therefore serve as a benchmark not only for scientific reasoning, but also for the metacognition of LLMs – and that is the main message of this work.
Comments


The Eleusis benchmark shows how well different LLMs do and how overcautious vs reckless they get. Higher score denote better performance at the task (from Louapre, 2026).
That’s for the summary. All this left my cognitivist mind buzzing. I think the idea of using Eleusis as a scientific and metacognitive benchmark for AI is both elegant and direct. That said, I do have two fairly serious objections, which will require a brief detour through cognitive psychology.
Is Eleusis a valid test?
The first objection regards the validity of the measurement. This should not be confused with reliability, which reflects the stability of a measurement (a thorny issue in human research, but not as much with AIs that can be tested independently for thousands of times on the same task). Validity refers to a measure's ability to actually measure what it claims to be measuring. First of all, while Eleusis clearly falls within the hypothetico-deductive approach, can we really say that being good at science reduces to that alone?
But this criticism is generic and not particularly operational, so I turned instead to the scientific literature and found a 2017 review of measures of scientific reasoning. That paper reviewed 38 tests covering domains such as hypothesis generation, data generation, data evaluation, and conclusions. I don't have the expertise to tell you whether all 38 of those tests are better measures of scientific reasoning than Eleusis. But I do doubt that coming up with a new test, based on a didactic game, is the optimal strategy for assessing the scientific abilities of LLMs.
The dig task and the mine task
Beyond this general criticism about measurement validity, I also have concerns about the way scores obtained on this task are supposed to reflect LLMs' ability to monitor their own cognitive performance. As a psychology researcher, this naturally made me think of metacognition. In the metacognition literature, "second-order performance" refers to a system's ability to evaluate its performance on a task (the "first-order performance"). But this benchmark also made me think, perhaps because of my background in psychophysics, of the notion of liberal and conservative behaviour. Nothing to do with politics: here, "liberal" and "conservative" is more neutral jargon for "bold" and "cautious". For a given detection ability (or, here, rule-identification ability), a liberal observer will tend to act more quickly, while a conservative observer will wait to accumulate more evidence or signal before committing to a decision.
You need to start confronting these two notions (first/second-order performance, liberal/conservative criterion) to realise that the difference between them is precisely what poses a problem for this benchmark. Let’s take a silly example. Imagine that, through training, well-directed prayers, or too much time spent next to a microwave, an individual develops the ability to detect metal. You bring them into the lab and find that over 100 trials (50 with metal, 50 without), they correctly detect metal 80 times – not perfect, but not bad. Now imagine that someone (President Snow or the Squid Game host) designs two tasks for them: the ‘dig task’ and the ‘mine task’.
In the 'dig task', they must walk in a straight line for 10 minutes, going as far as possible while digging up metal scrap buried roughly 50 cm underground. Every 100 metres walked earns them £1 and every piece unearthed earns £2, but digging takes time - time during which they could have covered 180 metres instead. Obviously, at the slightest doubt, our metal detector will prefer to keep walking. Their behaviour will be conservative: for the same signal, they'll tend to conclude the target is not present to avoid taking the risk to waste time and money.
Now take the same individual and put them through the ‘mine task’. This time, instead of metal scraps, there are anti-personnel mines buried in the ground, and they must reach the far end of a path. The faster they arrive, the more money they earn as a reward – but failing to defuse a mine will blow one of their legs up. This time, at the slightest doubt, they'll surely prefer to take the time to defuse the mine, even if they're not 100% certain they detected one. Their behaviour will become "liberal": for the same signal, they'll have a tendency to conclude that the target is present.
This little thought experiment illustrates that beyond first-order performance (the ability to detect metal) and even second-order performance (the confidence the individual has in their decision), the characteristics of the task play a major role in the decision the observer makes. The Eleusis benchmark proposes to identify the most well-calibrated LLMs, those with the best metacognition, by their ability to find the equilibrium point between overly liberal behaviour (penalised by a 2-point loss) and overly conservative behaviour (penalised by a 1-point loss). The problem is that this equilibrium point is itself heavily dependent on the task parameters. This principle of matching one's decision criterion to the task is so fundamental that it appears not only in decision-making and signal detection tasks, but also in the context of motor learning. For example, in an experiment by Trommershäuser et al., participants changed the way they pointed at a target depending on the penalty they received for touching a forbidden zone. The crucial result was that motor behaviour changed not only from one participant to another, but above all from one set of parameters to another: when the penalty was lower, participants shifted their pointing movement less. (Even more elegant: this shift was very well described by a statistically optimal model, once again proving that humans are cool.)
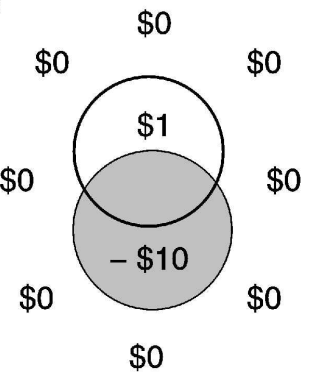
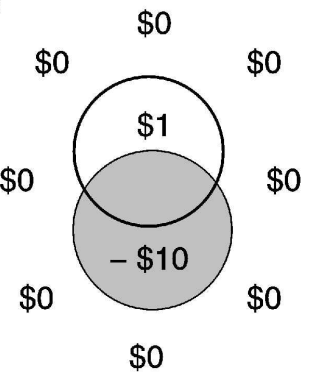
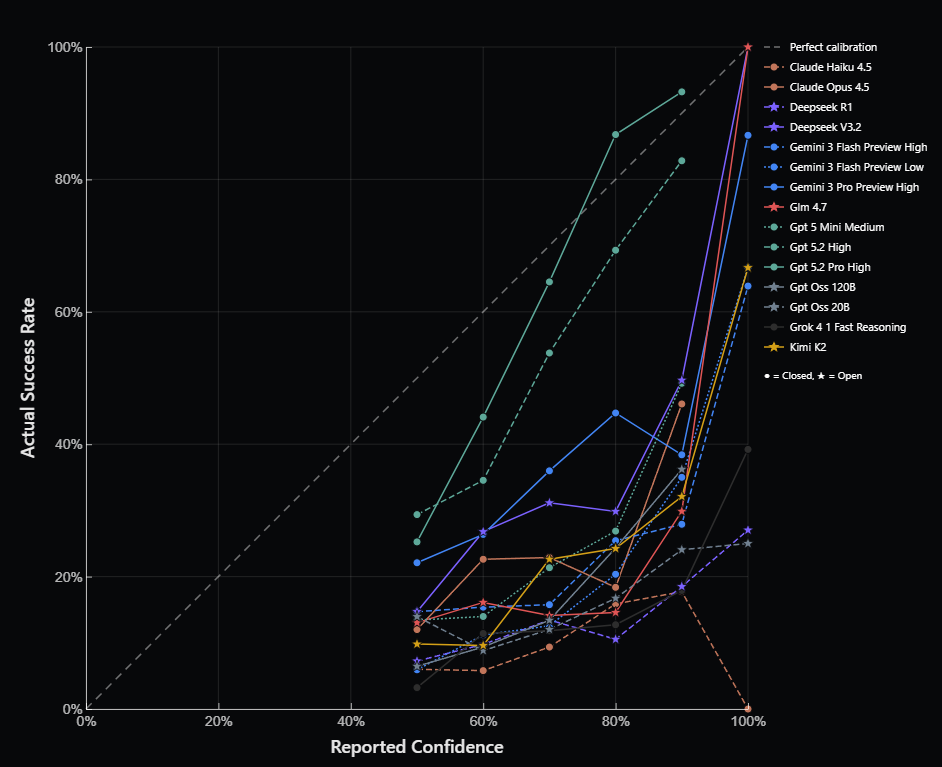
LLMs' actual success rate when guessing the rule vs. their reported confidence before choosing whether they take a guess (from Louapre, 2026).
Let’s go back to the benchmark. This implementation of Eleusis penalises false positives (wrong guesses) slightly more than false negatives (holding back the correct rule). But what would happen if the penalty for a wrong guess changed and became -5 points instead of -2, without the LLMs adjusting their behaviour accordingly? For an equal ability to identify the rule, more cautious models like GPT 5.2 Pro would then be heavily favoured and would appear far more reasonable than wilder models.
Personally, I would argue that putting all your energy chasing a dead end is generally far more damaging for a scientist than missing an opportunity. That may just be my personality, but it may also be tied to our publication system, which rewards incremental discoveries, while spending ten years on a ‘risky’ topic, as an early career researcher, amounts to professional suicide. A researcher working in an AI startup would likely see things quite differently as risk-taking looks much more rewarded there.
This objection could be addressed fairly simply by varying the task parameters of Eleusis, for instance by creating a dig-task-like conservative variant and a mine-task-like liberal variant, and measuring the extent to which LLMs adjust their response criterion accordingly. I don’t think I have the technical skills to do this myself, but looking at the data already shared by David Louapre, my intuition is that GPT 5.2 Pro would fare reasonably well: even if Gemini 3 Pro came out ahead under these particular parameters, the confidence reported by GPT at each trial (before making a decision) was visibly better aligned with its actual success rate than Gemini's was (see below).
From Trommershäuser et al. (2003) - hitting the penalty zone results in a large loss that participants will tend to avoid by aiming outside the actual target.
In any case, beyond the specific question of the Eleusis benchmark, the LLM boom is an exciting opportunity for cognitive science to strengthen the dialogue between psychology and AI, and for that alone, I am grateful to David Louapre for his contribution and his work in science communication.